 Among the factors which interact to determine whether or not the cost of running the combined workload on the consolidation
machine is less than the cost of running it on the original gear, two stand out:
Among the factors which interact to determine whether or not the cost of running the combined workload on the consolidation
machine is less than the cost of running it on the original gear, two stand out:
This is a draft for my LinuxWorld.com series. Please do not copy or distribute this without the permission of Linuxworld.com.
This is the second of three articles in which Paul Murphy takes a close hard look at running Linux on the mainframe.
In this one he investigates the rationale for running Linux under VM and explains for whom and under what circumstances he believes pursuing this might make sense.
The first article showed that:
There seem to be no clearly defined, third party, audited benchmarks giving the price performance ratio of the zSeries relative to other Unix machines like Linux or BSD on the PC or Solaris on SPARC.
| The view from outside the box |
|---|
|
The dominance of the better solution is an important issue at both technical and
business levels. A solution may be the best choice in its own context and still
be a poor choice when viewed from outside that context.
Consider an exaggerated example: imagine yourself arriving at an airport 50 miles from your actual destination and being offered three choices for covering the remaining distance:
If you restrict the decision to cycles, that in-line, two seat, bicycle is going to look quite attractive --especially after you crash the unicycle a few times. For people who can only use cycles, the bicycle choice makes sense but people who don't face this restriction will almost always see the car rental as the prefered, or dominant, alternative. |
From a market niche identification perspective IBM's key claims for Linux on the zSeries are that it:
If we look at these carefully it becomes obvious that none define viable markets for the Linux on mainframe concept because people who need these facilities almost always have significantly better options available to them.
64 Bit Development Environment
The z800 and z900 are IBM's first 64 bit mainframes and Linux versions tailored to this machine have yet to be widely proven in practice. Meanwhile:
For some ISVs porting to a mainframe Linux may make sense, but not for cost or performance reasons associated with the transition to 64 bit addressing. If getting to 64 Bits without waiting for AMD's sledgehammer x86 product is important to you, get a Sun V100 for about $995 --it isn't much of a machine by today's standards but it's likely to be cheaper and faster than a five year old SPARC, Alpha, or HP box off Ebay and gets you into both the Solaris and Linux 64 bit game without forcing you to learn VM/CMS first.
Isolation
The isolation argument is that each ghost (guest operating system) can be treated independently in situations where it doesn't matter that multiple ghosts share many things --like disks, I/O channels, communications, management, and the basic machine.
VM is very good at this, but you don't need a mainframe to achieve this effect. Both vmware at the hardware level and Virtuozzo at the Linux level can give you similar benefits without the cost and complexity of the mainframe.
In addition, the communities/containment facility available within trusted Solaris can be combined with the resource manager to provide a technically smarter solution to most isolation needs than ghosting --one that avoids the overhead of environment switching while allowing the normal scheduler to dynamically handle resource allocation.
Server Consolidation
The basic IBM premise is that you can move processing from "ten to hundreds" of real Linux machines to Linux ghosts running on the mainframe. Notice that this is a one to one mapping: one real Linux box gets replicated as one Linux guest under VM so 100 real machines become 100 virtual ones with their applications carried across intact.
This is in some ways a new idea. Most previous server consolidation efforts have been focussed on moving from many small boxes to one larger machine through service consolidation.
Suppose, for example, that you had bought something like Oracle Financials in 1996 and deployed a bunch of Unix servers to run the database, the applications, and ad-hoc reporting. By now you might have an HP K-580 running Oracle, a pair of Sun 450s running the application, and a dual processor J-Class dedicated to adhoc reporting. This highly fragemented structure made sense at the time it was put in because getting the high end power to run everything on one machine was more expensive than setting up linkages between four smaller machines. Today, however, mid range power has become much cheaper and it probably makes more sense to consolidate all of the workload to one machine than to continue with the complexity of the existing set-up.
| This isn't a dumb as it sounds. I've worked in situations in which unentangling the inter-applications linkages, files, and permissions involved in making some complicated small machine scenario work was extremely difficult and risky. In one case, about three weeks after we brought up the system on one machine, a monthly file transfer failed because the script controlling it linked to a machine that was no longer there - causing several hundred users to be extremely frustrated with me the next morning when the files hadn't been updated. |
What IBM is offering is a half-way house kind of choice. Instead of consolidating both workload and hardware by moving everything to one machine, you can choose to consolidate only the hardware while retaining the linkages and other work-arounds needed to spread the load across four machines.
To understand how this idea affects the market we need to ask ourselves under what circumstances it might make sense to do it - because those circumstances would then characterize a market niche for this product offering.
From a business perspective this kind of hardware, but not workload, consolidation makes sense if:
On close examination it turns out, however, that these conditions are rarely, if ever, met in well managed Unix environments. That's because it can only happen if three things are all true:
Among the factors which interact to determine whether or not the cost of running the combined workload on the consolidation
machine is less than the cost of running it on the original gear, two stand out:
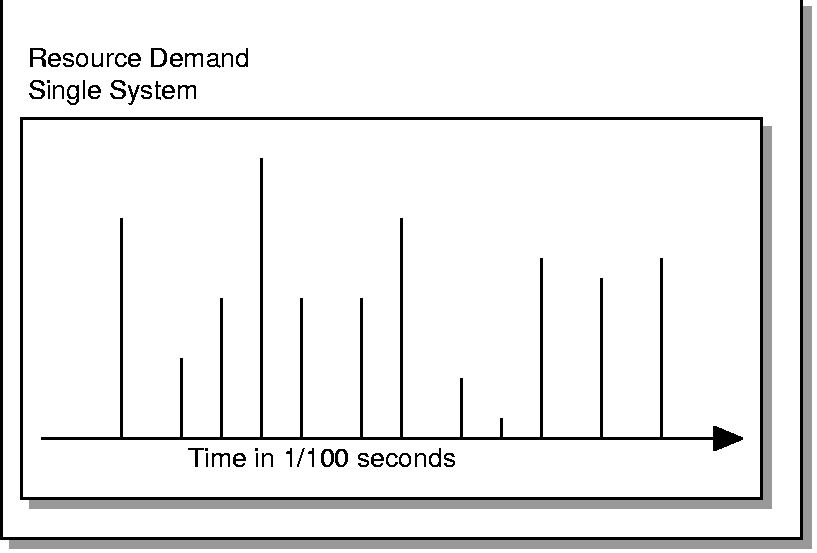
Consider the single machine arrival pattern shown above. The essence of consolidation is to slide additional workload into the empty time slots between resource use (shown as demand spikes). If the arrival pattern is reasonably close to random and the machines are significantly underutilized, then the consolidation server doesn't have to be faster than the source machines. In this situation a few resource demands arrive while the consolidated system is busy and get pushed one time slice forward but most fall into idle periods and are served just as quickly as they were on the original dedicated machine.
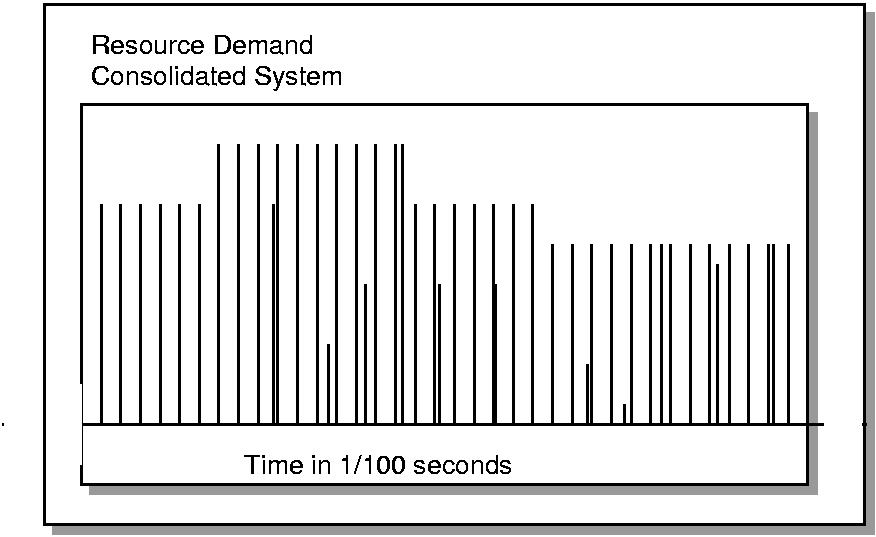 Here's what the pattern looks like if five workloads, each of which used less than 15% of machine
capacity on the original hosts, are consolidated onto one comparably scaled machine.
Here's what the pattern looks like if five workloads, each of which used less than 15% of machine
capacity on the original hosts, are consolidated onto one comparably scaled machine.
However, the more the pattern of arrival times diverges from random, the more likely it is that resource demands will become additive; stacking up in the same time slots with new ones arriving too often for the system just to delay processing into the next empty slot. To deal with that you either:
For both Unix and mainframe users costs tend costs tend to go up much faster than system scale so this quickly becomes a losing proposition. The cost escalation rate is, however, much lower for the Unix guy than for his mainframe counterpart so, within limits, the usual Unix strategy is to get more power while the usual mainframe strategy is to delay user processing.
In this diagram, for example, the same basic workload sketched earlier is replicated
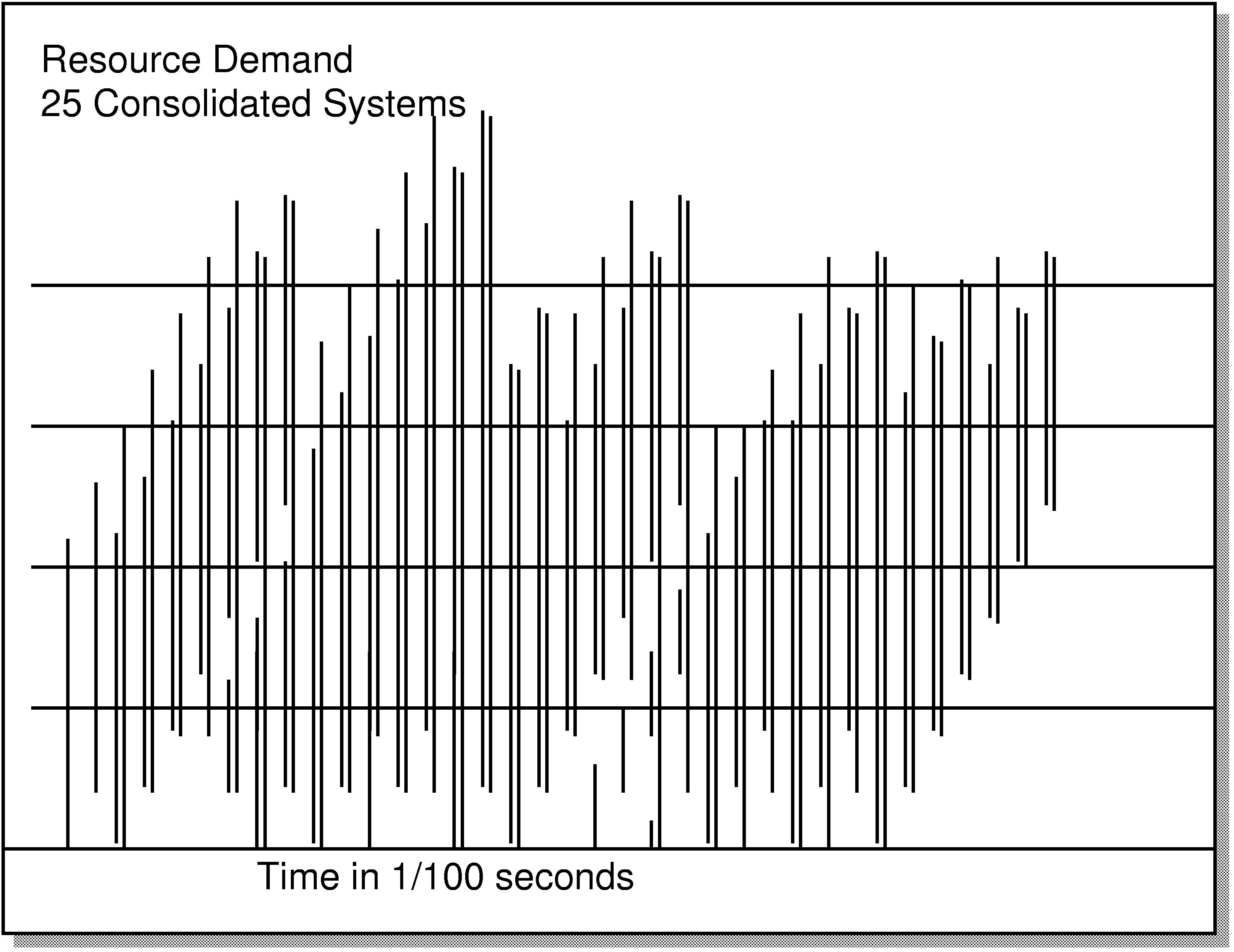 25 times. To meet that demand, you need a machine with somewhere around five times the processing power of the
original hosts.
25 times. To meet that demand, you need a machine with somewhere around five times the processing power of the
original hosts.
In both cases you get the biggest bang for the consolidation buck when replacing obsolete gear but even then you're usually limited to a factor of ten or so. Thus consolidation works financially if you're upgrading twenty-five 200Mhz Pentium Pro servers that have been running SCO since about 1995 to one Linux server with a couple of Xeons, because you get the extra power from the realization of Moore's law during those seven years. If, on the other hand, you looked at doing this with twenty-five dual processor Xeon's running at 550Mhz, you'd almost certainly find today's replacement cost prohibitive.
Most scenarios in which resource demand is user generated fail on the randomness criterion - meaning that peak demand is more typically additive than interpolative.
In most cases service demands cluster at specific times --people check their email when they arrive at the office mainly in the early morning, play on the internet from home mainly in the evenings, start up major applications right after breaks, and so on. Effective consolidation for these types of applications therefore usually requires either a willingness to delay user processing or the ability to meet something closer to the sum of peak demands placed on the source machines rather than just their average.
Since the mainframer's entire professional view is focussed on managing the resource, delaying user processing to fit the resource constraint is the obvious right answer. To a Unix manager, however, this belies the purpose of having systems -to serve user needs- and the right answer is therefore to get more power or not consolidate. As discussed in my defenstration guide this very basic conflict in viewpoint is one reason so many Unix installations run by traditional data processing people turn into financial and operational disasters.
Many apparent consolidation candidates also fail on the business reasons criterion. Most business reasons for having multiple Linux (or other Unix) instances on small machines tie to workloads that have large instantaneous peaks (e.g. GRID computing); continuous (non random) workloads (e.g. the google search engine runs on thousands of Linux servers); business contracts that call for independent hardware (ASP services), or are geographically dispersed.
The latter issue is particularly important. If a company has multiple locations, putting local DNS, database, and/or file servers in those locations is often justified for network performance and cost reasons having nothing to do with server or server operating costs --and often done more to give local users a sense of system ownership than to save money. Either way, consolidation does not make sense.
To construct a scenario in which Linux, or other Unix, server consolidation would make sense you have to assume a pre-existing condition with lots of little boxes all in one place and all running basically the same applications at very low levels of utilization and no business rationale for doing it.
As IBM delicately puts it in Linux on IBM zSeries and S/390: ISP/ASP Solutions:
It turns out that server consolidation is most viable when there is some inefficiency in the current operation. [Chapter 2, Page 26]
Or, more bluntly: it generally takes either an aging infrastructure or serious mismanagement to create a situation in which Unix server consolidation makes sense.
Unhappily, this is relatively common. What seems to happen is that a practice which responds to problems with Windows operating environments and applications - using rackmounts as a kind of surrogate for highly reliable SMP capabilities - is carried over to Unix despite the fact that the problems to which it responds don't exist in Unix.
Cleaning this up through workload consolidation -in which you merge workloads on one or two larger servers and shutdown or re-allocate the rest- makes sense, but replicating the mess by virtualizing each of the redundant boxes on a mainframe just perpetuates a bad practice. If you don't need N Linux boxes in the data center, you don't need their ghosts inhabiting your mainframe either.
According to a May, 2001 presentation
by David Boyes it is possible to emulate a 200MHZ NT box on the mainframe:
Hand optimization of code will address speed concerns |
Server consolidation often does, however, make sense where the organization has rackmounts of Windows servers in the same physical location. People set them up that way mainly for one or both of two reasons:
Of course if you consolidate from NT to Windows 2000, or from any Windows product to any Unix, workload consolidation (putting more work on one machine) will generally be smarter than hardware consolidation (replicating small servers on a larger one). That's because cleaning up a mess that consists of too many OSes running on too many boxes by getting rid of a few boxes addresses only half the problem --you'll generally be better off loading Linux on some of those servers, using them to consolidate the workload, and shutting the rest down.
After all, if you don't have the problem, you don't need the solution.
Considerations like these, even if only approximately correct, would make you think that Linux on the mainframe has no role in a well run business. In the long run that may well be true, but in the medium term it isn't because the mainframe community continues to play an important role in corporate data processing --and isn't going to run Linux in any other way.
We've been looking at this from the perspective of the uninvolved third party with a knowledge of Unix. From this perspective most of the claims being made don't make much sense, but look at those same ideas from inside the mainframe community and the change in perspective changes both what you see and how you interpret it.
From inside the community the decision doesn't look like a choice between a $5,000 Dell and a $500,000 mainframe, it looks like a choice bringing, or not bringing, Linux, and Linux ideas, into the environment.
Again this is very much a matter of perception and viewpoint. There's the old joke that being surrounded by hungry aligators makes it difficult to remember that your mission is to drain the swamp. If you look at the typical mainframe data center from the outside you tend not to see a role for ghosting and to think that the mainframe, and, more importantly, the management methods around it, should be replaced. From the inside, however, those aligators sound hungry and mainframe Linux looks like an attractive means of feeding or distracting at least some of them.
From inside the mainframe environment, using Linux guests looks like one more tool among many aimed at bringing order and control to resource usage and demand. From that perspective Linux guests offer numerous advantages including the ability to maintain separate instances mirroring code releases, use of tools like apache for web based report delivery without affecting disaster recover plans, or deployment of several Linux instances as a way of forcing a hard separation on multiple samba instances without having to support a server farm.
As a general thing mainframe data center management is extremely concerned about issues like "systems manageability" - meaning the ability to manage the resource by allocating priorities and capacity. From their perspective this is usually the most important of their managerial functions so the ability to have VM dynamically re-allocate resources between guest operating systems offers a nearly magical solution to a pressing need for better control.
The trouble is that the need for this type of control only exists because of the mainframe's processing limitations. If you don't have the problem, you don't need the solution.
In the mainframe world the problem is the scarcity and cost of the processing resource. A 16 CPU, 64GB system appears to list at about five million bucks and a monthly support cost in the range of $26,000 before disk, tape, software, or staffing. The solution is resource management, capacity planning, process prioritization, and applications control of the kind that zVM and its associated toolsets excel at.
Similar Unix power, whether on a RSIC box or a rack of high end Intel servers runs to perhaps 10% of that cost inclusive of pheripherals and software. That cost difference changes the picture, take away the resource scarcity, and the skills and tools needed to allocate resources become less than valueless -they become boat anchors dragging down the business. As noted earlier, I think this is a key reason so many large Unix installations are disasters - they're run by people who go right on solving a resource scarcity problem they no longer have.
What's fundamentally going on is the continuation of a very long term trend away from batch and toward purely interactive processing. That process has been going on since the mid fifties split between scientific -meaning interactive- and commercial -meaning batch- computing.
Over the years IBM has tried, in response to both technical and business needs, to introduce more and more ideas and code bridging this gap into its mainframe products. Today, I suspect, the split exists far more clearly in the management methods and ideas that surround the mainframe than in either the machine or its operating systems but IBM continues, nevertheless to be captive to the dollars and organizational clout wielded by the mainframe community.
|
IBM's Future Systems project took place in about the same time period (1968 to 1973) that people
at AT&T/Bell Labs were inventing Unix and was driven by many of the same ideas. The system demonstrated
in 1973 completely obsoleted the System 360 it was meant to replace and included both a highly interactive
focus and a data centric design akin to PICK (and the promised 2004/5 "Blackcomb" series of Windows
OS products).
In 1972, however, IBM's 360 customer base wanted a faster, more capable, 360, not a whole new set of ideas based on interactive processing and shifting business control back to the user community they had just wrestled it away from. More recently IBM has tried to bring Unix ideas into the mainframe world by providing POSIX compliant libraries and run-time support within MVS/XA (now zOS) but its mainframe customers have reacted just as they did when the Future System finally hit the market in 1979 (as the System 38) --by staying away in droves while spending big dollars on such 360 era stalwarts as CICS, IMS, and COBOL instead. |
Most other mainframe manufacturers from the seventies and eighties have abandoned this market in favor of Unix or Windows servers but I don't think that IBM has that option. If I understand it correctly, most of their profit comes from leveraging four to five dollars in high margin licensing and services revenue for every dollar brought in through enterprise server sales. The mainframe community powers IBM's market image, abandon the mainframe and two things would probably happen:
If we assume, therefore, that the trend toward Unix style interactive processing and resource management will more probably continue to be long term than short, it makes sense to look at mainframe Linux solely from the perspective of those inside the community. These are the people the aligators are biting, and from their perspective there are at least two situations in which running Linux on the mainframe may reasonably be expected to make business sense:
Of course, if doing this is reasonable for some customers, then this creates an opportunity for others to serve those customers and lets us identify a third category of user to whom mainframe Linux should make business sense: those who want to sell Linux-on-mainframe products.
Be aware, however, of the cultural differences; this is not the Unix marketplace
you are likely to be used to. Some tips:
|
Running Linux on the mainframe makes perfect sense if you intend to sell into that market.
If you are, or can be, a commercial software developer and have people with the skills and contacts to sell into the mainframe community, then doing so offers obvious opportunities.
Although companies like Gartner track the mainframe software and services markets, verified, publically available, numbers are hard to come by. Consider, however, IBM's claim (below) that there are about 14,000 CICS customers worldwide and assume that, on average, each one spends about 40 million per year on data processing and related services. Most of that goes for salaries, but if only 3% were available for new projects this would amount to a 16 billion dollar market.
My perception is that IBM is very good at account control and that selling against them into an IBM account is therefore extremely difficult. On the other hand, I believe that they have excellent partnering programs that offer you both improved access to the customer and reduced business risk in exchange for acknowledging and protecting that account control.
What this means is that if you've got a product to sell and the people to do it, running on mainframe linux (particularly if that mainframe is owned and operated by IBM as your business partner) should be great way to go.
There are at least two situations in which using mainframe Linux as a bridge technology would make probably make sense:
Legacy Linkages
Virtually all major organizations have either incorporated web technologies into their businesses or are under significant pressure to do so. IBM's Unix facility for MVS should have allowed the mainframe community to adapt to this during the nineties but very few even started moving out of token ring and SNA style networking until IBM forced the issue by standardizing on TCP/IP. As a result many data centers managers now need to find short term ways to patch legacy applications running on the mainframe into a web enabled framework of some kind.
| Using linux for either of these isn't actually necessary since both ideas could just as well be implemented using Unix System Services directly under zOS (see, Chapter Seven: Unix System Services, in this zOS implementation manual for a guide to running Unix applications under zOS.) but this, of course, wouldn't be nearly as cool. |
IBM's premier offering for this is IBM Websphere -a wide ranging set of tools, services, and prebuilt applications components that runs on just about everything IBM sells and can effectively link almost as many (if not more) different applications architectures as their MQ-Series middleware.
For example, an IBM press release on using websphere to link CICS [Customer Information Control System; a 60s transactions control environment] to the web based applications has this to say:
|
That's about 71 programmers to process 2.1 million transactions per day per site.
We don't know how complex these transactions are. If we use the TPC/C V5 order entry transaction as a surrogate measure, this per site workload could take up to six minutes on an HP Superdome or, if we use the Sanchez financial transaction benchmark as an approximation, a bit less than five on a Sun 6800. |
Building on the proven strengths of CICS, CICS Transaction Server V2.1 now allows e-business applications access to traditional CICS data and applications through Enterprise Java Beans efficiently deployed within CICS. Through shared technology with WebSphere, it provides integration with modern development environments such as the Enterprise Java platform and Web Services while reducing both the cost of writing new applications and time to market for deployment of applications.
This new product will continue to enhance the reputation of CICS, which is recognized as the leading transaction server in the industry. CICS processes more than 30 billion transactions per day and more than $300 billion in transactions per week. CICS has 14,000 customers around the world and one million programmers.
The first type of application for this is obvious. Since Websphere runs on Linux, a data center manager can meet externally generated demand for web access to legacy data by using zVM to put ghosted Linux servers on the same machine, or machines, that run the CICS applications generating the data.
A second, perhaps less obvious, use is print distribution. Using Linux on the mainframe to run an apache page server can provide tremendous cost reductions, and ease of use improvements, on reporting because it can allow the data center to avoid the cost of printing and distributing physical reports.
Terminal Services
IBM does not seem to mention terminal services or desktop consolidation as a possible use for mainframe Linux. I assume this is because the mainframe would have trouble handling the interrupts generated but it should nevertheless be technically feasible to connect at least some desktop netvista smart displays to mainframe based Linux ghosts. That would provide the equivalent of desktop Linux services while reducing the complexity of the support requirements that go with any desktop OS.
In the Windows world you can do this with Citrix - putting a virtual PC on a server for each real PC on user desktops and then accessing that via the Terminal Server Client built into Windows. In the Unix world you put smart displays on desktops and consolidate user workloads on one or two larger machines.
| The smart display |
|---|
|
Smart displays are third generation X-terminals providing powerful graphics
support and local image processing.
|
In the IBM mainframe world, however, most legacy applications requiring user interaction achieve this with character based, block mode, terminals. When you type on a PC or Unix display every keystroke or mouse action is transmitted to the CPU and causes an interrupt. In the mainframe world block mode devices avoid the overhead associated with this and only transmit complete units (usually pages). As a result these applications now tend to seem woefully out of date and clumsy.
With Linux on the mainframe, however, data center managers could replace those block mode terminals with smart displays by linking the Linux ghost to the legacy application using a "guification" tool. That would then let them extend the life of those applications while providing additional value to users via such things as the OpenOffice.org toolset or the provision of standard Unix ecommunication services.
There's an industry joke with the usual tinge of bitter truth that the most common cause of an abend (abnormal batch termination) in a well run data center is an In-Flight magazine --because nothing else is quite as much of a threat to smooth operations as a senior executive with a half baked idea.
Whatever the proximate cause, most data center managers will encounter situations in which:
In these situations, using Linux on an existing mainframe makes perfect sense for both political and technical reasons. Politically adopting Linux shows commitment and with-it-ness while technically the actual project can be isolated, its risks managed, and its time scales reduced by piloting the project implementation on Linux and only then deciding whether the resource consumption involved warrants re-development as a mainframe application.
Outisde the mainframe community the primary issues are cost and credibility. We know approximately what the costs are: about five million for your basic 16 processor mainframe with 64GB, but we don't have good performance data to weigh that cost against.
Where the credibility aspect is wholly determined by the customer's allegiance to IBM, price and performance are non issues but, for everyone else, real numbers are needed before serious judgments can be made.
This, I think, is the primary issue for IBM. Their committed customers will, and probably should, buy into this technology. It is, after all both from IBM and really "way cool" whether it makes business sense or not.
Other people, however, are likely to be less enthusiastic unless IBM shows them real evidence of competitive value; something they have yet to do convincingly.
Speaking personally, I started out expecting Linux on the mainframe to make sense but IBM's stonewall response on cost and benchmark information, their sputterings about undefined value propositions, and their reliance on questionable third party "tests" and "studies" completely over rode any further willingness on my part to suspend disbelief.
To resolve the clouds of doubt among non IBM loyalists, we need clear, public, benchmarks and widely replicated tests. That's what next week's article is about: asking IBM to play by the same rules everyone else does.
 The 1973 IBM portable computer
The 1973 IBM portable computer